引言
讽刺的是,抽象和形式化的任务对人类而言是最困难的脑力任务之一,但对计算机而言却属于最容易的。计算机早就能够打败人类最好的象棋选手,但直到最近计算机才在识别对象或语音任务中达到人类平均水平。一个人的日常生活需要关于世界的巨量知识。很多这方面的知识是主观的、直观的,因此很难通过形式化的方式表达清楚。计算机需要获取同样的知识才能表现出智能。人工智能的一个关键挑战就是如何将这些非形式化的知识传达给计算机。
些人工智能项目力求将关于世界的知识用形式化的语言进行硬编码(hard code)。计算机可以使用逻辑推理规则来自动地理解这些形式化语言中的声明。这就是众所周知的人工智能的知识库( knowledge base)方法。然而,这些项目最终都没有取得重大的成功。其中最著名的项目是 Cyc(Lenat and Guha,1989)Cyc包括一个推断引擎和一个使用CycL语言描述的声明数据库。这些声明是由人类监督者输入的。这是一个笨拙的过程。人们设法设计出足够复杂的形式化规则来精确地描述世界。例如,Cyc不能理解一个关于名为rred的人在早上剃须的故事( Linde,1992)。它的推理引擎检测到故事中的不一致性:它知道人体的构成不包含电气零件,但由于Fred正拿着一个电动剃须刀,它认为实体“正在剃须的Fred”(“ Fred While Shaving”)含有电气部件。因此它产生了这样的疑问—Fred在刮胡子的时候是否仍然是一个人。;)
依靠硬编码的知识体系面对的困难表明,AI系统需要具备自己获取知识的能力即从原始数据中提取模式的能力。这种能力被称为机器学习( machine learning)引入机器学习使计算机能够解决涉及现实世界知识的问题,并能作出看似主观的决策。比如,一个被称为逻辑回归( logistic regression)的简单机器学习算法可以决定是否建议剖腹产(Mor- Yosef et al,1990)。而同样是简单机器学习算法的朴素贝叶斯( naive Bayes)则可以区分垃圾电子邮件和合法电子邮件
这些简单的机器学习算法的性能在很大程度上依赖于给定数据的表示( repre-sentation)。
许多人工智能任务都可以通过以下方式解决:先提取一个合适的特征集,然后将这些特征提供给简单的机器学习算法。例如,对于通过声音鉴别说话者的任务来说,一个有用的特征是对其声道大小的估计。这个特征为判断说话者是男性、女性还是儿童提供了有力线索。
然而,对于许多任务来说,我们很难知道应该提取哪些特征。例如,假设我们想编写一个程序来检测照片中的车。我们知道,汽车有轮子,所以我们可能会想用车轮的存在与否作为特征。不幸的是,我们难以准确地根据像素值来描述车轮看上去像什么。虽然车轮具有简单的几何形状,但它的图像可能会因场景而异,如落在车轮上的阴影、太阳照亮的车轮的金属零件、汽车的挡泥板或者遮挡的车轮一部分的前景物体等等。
解决这个问题的途径之一是使用机器学习来发掘表示本身,而不仅仅把表示映射到输出。这种方法我们称之为表示学习( representation learning)。学习到的表
示往往比手动设计的表示表现得更好。并且它们只需最少的人工干预,就能让AI系统迅速适应新的任务。表示学习算法只需几分钟就可以为简单的任务发现一个很好的特征集,对于复杂任务则需要几小时到几个月。手动为一个复杂的任务设计特征需要耗费大量的人工时间和精力;甚至需要花费整个社群研究人员几十年的时间。
表示学习算法的典型例子是自编码器( autoencoder)。自编码器由一个编码器( encoder)函数和一个解码器( decoder)函数组合而成。编码器函数将输入数据转换为一种不同的表示,而解码器函数则将这个新的表示转换到原来的形式。我们期望当输人数据经过编码器和解码器之后尽可能多地保留信息,同时希望新的表示有各种好的特性,这也是自编码器的训练目标。为了实现不同的特性,我们可以设计不同形式的自编码器。
当设计特征或设计用于学习特征的算法时,我们的目标通常是分离出能解释观察数据的变差因素( factors of variation)。在此背景下,“因素”这个词仅指代影响的不同来源;因素通常不是乘性组合。这些因素通常是不能被直接观察到的量。相反,它们可能是现实世界中观察不到的物体或者不可观测的力,但会影响可观测的量。为了对观察到的数据提供有用的简化解释或推断其原因,它们还可能以概念的形式存在于人类的思维中。它们可以被看作数据的概念或者抽象,帮助我们了解这些数据的丰富多样性。当分析语音记录时,变差因素包括说话者的年龄、性别、他们的口音和他们正在说的词语。当分析汽车的图像时,变差因素包括汽车的位置、它的颜色、太阳的角度和亮度。
显然,从原始数据中提取如此高层次、抽象的特征是非常困难的。许多诸如说话口音这样的变差因素,只能通过对数据进行复杂的、接近人类水平的理解来辨识。这几乎与获得原问题的表示一样困难,因此,乍一看,表示学习似乎并不能帮助我们。
深度学习( deep learning)通过其他较简单的表示来表达复杂表示,解决了表示学习中的核心问题。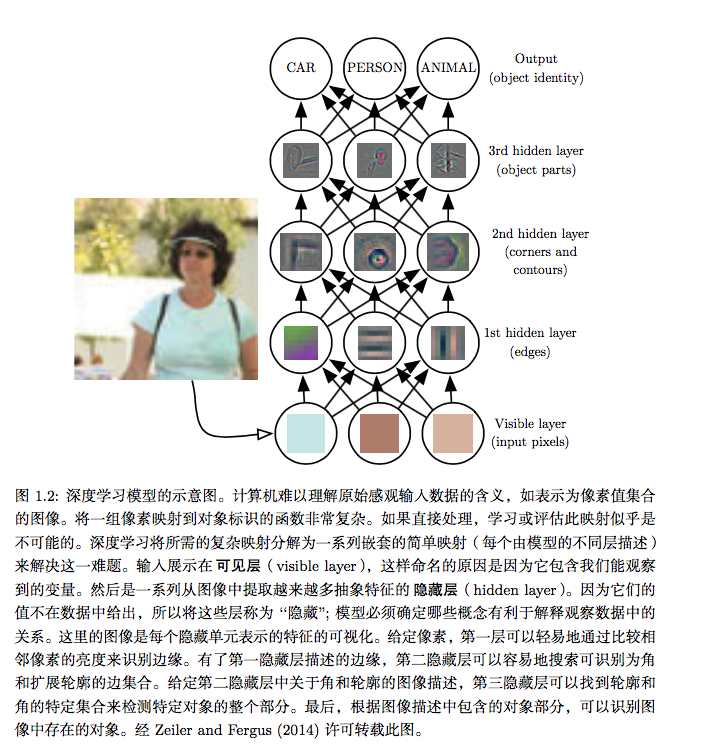
如何通过组合较简单的概念(例如转角和轮廓,它们转而由边线定义)来表示图像中人的概念。深度学习模型的典型例子是前馈深度网络或多层感知机( multilayer perceptron,MLP)。多层感知机仅仅是一个将一组输人值映射到输出值的数学函数该函数由许多较简单的函数复合而成。我们可以认为不同数学函数的每一次应用都为输入提供了新的表示。
学习数据的正确表示的想法是解释深度学习的一个视角。另一个视角是深度促使计算机学习一个多步骤的计算机程序。每一层表示都可以被认为是并行执行另组指令之后计算机的存储器状态。更深的网络可以按顺序执行更多的指令。顺序指令提供了极大的能力,因为后面的指令可以参考早期指令的结果。从这个角度上看在某层激活函数里,并非所有信息都蕴涵着解释输入的变差因素。表示还存储着状态信息,用于帮助程序理解输人。这里的状态信息类似于传统计算机程序中的计数器或指针。它与具体的输人内容无关,但有助于模型组织其处理过程。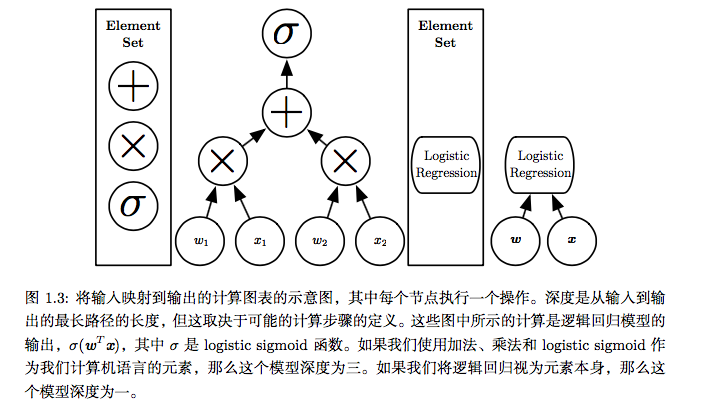
由于不同的人选择不同的最小元素集来构建相应的图,因此就像计算机程序的长度不存在单一的正确值一样,架构的深度也不存在单一的正确值。另外,也不存在模型多么深才能被修饰为“深”的共识。但相比传统机器学习,深度学习研究的模型涉及更多学到功能或学到概念的组合,这点毋庸置疑。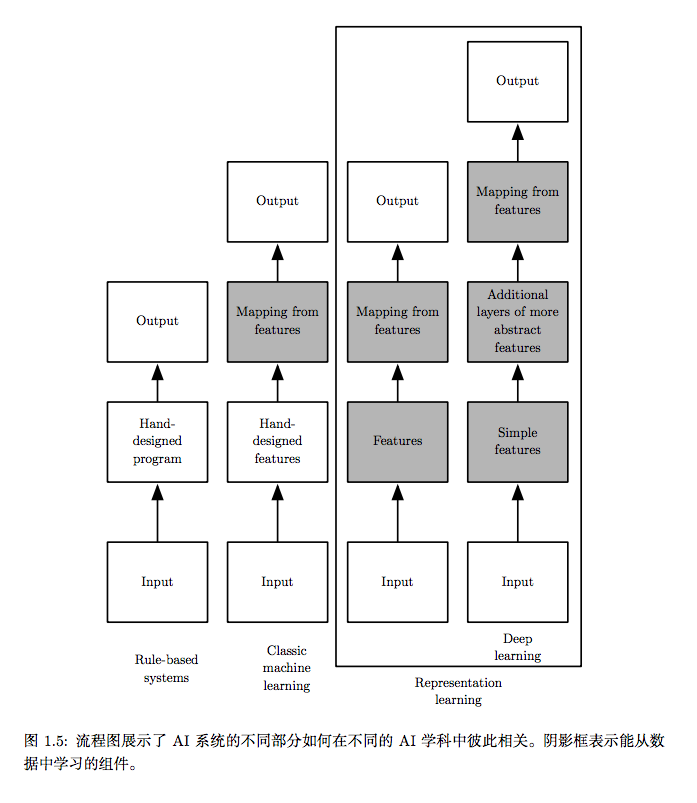
本书面向的读者
深度学习的历史趋势
神经网络的众多名称和命运变迁
20世纪40年代到60年代深度学习的雏形出现在控制论( cybernetics)中。
尽管有些机器学习的神经网络有时被用来理解大脑功能( Hinton and shallice,1991),但它们一般都没有被设计成生物功能的真实模型。
现在,神经科学被视为深度学习研究的一个重要灵感来源,但它已不再是该领域的主要指导。
媒体报道经常强调深度学习与大脑的相似性。的确,深度学习研究者比其他器学习领域(如核方法或贝叶斯统计)的研究者更可能地引用大脑作为影响,但是大家不应该认为深度学习在尝试模拟大脑。
深度学习领域主要关注如何构建计算机系统,从而成功解决需要智能才能解决的任务,而计算神经科学领域主要关注构建大脑如何进行真实工作的比较精确的模型。
在20世纪80年代,神经网络研究的第二次浪潮在很大程度上是伴随一个被称为联结主义( connectionism)或并行分布处理( parallel distributed processing)潮流而出现的( Rumelhart et al,1986d; McClelland et al,1995)。
联结主义的中心思想是,当网络将大量简单的计算单元连接在一起时可以实现智能行为。这种见解同样适用于生物神经系统中的神经元,因为它和计算模型中隐藏单元起着类似的作用。
其中一个概念是分布式表示( distributed representation)( Hinton et al,1986)其思想是:系统的每一个输入都应该由多个特征表示,并且每一个特征都应该参与到多个可能输人的表示。例如,假设我们有一个能够识别红色、绿色、或蓝色的汽车、卡车和鸟类的视觉系统,表示这些输人的其中一个方法是将九个可能的组合:红
卡车,红汽车,红鸟,绿卡车等等使用单独的神经元或隐藏单元激活。这需要九个不同的神经元,并且每个神经必须独立地学习颜色和对象身份的概念。改善这种情况的方法之一是使用分布式表示,即用三个神经元描述颜色,三个神经元描述对象身份。这仅仅需要6个神经元而不是9个,并且描述红色的神经元能够从汽车、卡车和鸟类的图像中学习红色,而不仅仅是从一个特定类别的图像中学习。分布式表示的概念是本书的核心。
联结主义潮流的另一个重要成就是反向传播在训练具有内部表示的深度神经网络中的成功使用以及反向传播算法的普及( Rumelhart et al,1986c; LeCun,1987)。这个算法虽然曾黯然失色不再流行,但截至写书之时,它仍是训练深度模型的主导方法。
在20世纪90年代,研究人员在使用神经网络进行序列建模的方面取得了重要进展。 Hochreiter(191b)和 Bengio et al.(1994a)指出了对长序列进行建模的些根本性数学难题, Hochreiter and schmidhuber(1997)引入长短期记忆( long short-term memory,LSTM)网络来解决这些难题。如今,LSTM在许多序列建模任务中广泛应用,包括 Google的许多自然语言处理任务。
神经网络研究的第三次浪潮始于2006年的突破。Geoffrey Hinton表明名为深度信念网络的神经网络可以使用一种称为贪婪逐层预训练的策略来有效地训练。
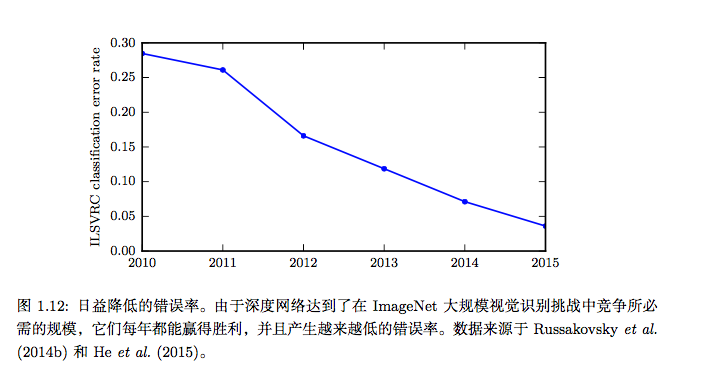
神经网络研究的这一次浪潮普及了“深度学习”这一术语的使用,强调研究者现在有能力训练以前不可能训练的比较深的神经网络,并着力于深度的理论重要。此时,深度神经网络已经优于与之竞争的基于其他机器学习技术以及手工设计功能的AI系统。
尽管深度学习的研究重点在这一段时间内发生了巨大变化。第三次浪潮已开始着眼于新的无监督学习技术和深度模型在小数据集的泛化能力,但目前更多的兴趣点仍是比较传统的监督学习算法和深度模型充分利用大型标注数据集的能力。
与日俱增的数据量
“大数据”时代使机器学习更加容易。截至2016年,一个粗略的经验法则是,监督深度学习算法在每类给定约5000个标注样本情况下一般将达到可以接受的性能,当至少有1000万个标注样本的数据集用于训练时,它将达到或超过人类表现。此外,在更小的数据集上获得成功是一个重要的研究领域,为此我们应特别侧重于如何通过无监督或半监督学习充分利用大量的未标注样本。
与日俱增的模型规模
20世纪80年代,神经网络只能取得相对较小的成功,而现在神经网络非常成功的另一个重要原因是我们现在拥有的计算资源可以运行更大的模型。联结主义的主要见解之一是,当动物的许多神经元一起工作时会变得聪明。单独神经元或小集合的神经元不是特别有用。
就神经元的总数目而言,直到最近神经网络都是惊人的小。自从隐藏单元引人以来,人工神经网络的规模大约每2.4年扩大一倍。这种增长是由更大内存、更快的计算机和更大的可用数据集驱动的。更大的网络能够在更复杂的任务中实现更高的精度。这种趋势看起来将持续数十年。除非有能力迅速扩展的新技术,否则至少要到21世纪50年代,人工神经网络将才能具备与人脑相同数量级的神经元。生物神经元表示的功能可能比目前的人工神经元所表示的更复杂。
现在看来,其神经元比一个水蛭还少的神经网络不能解决复杂的人工智能问题是不足为奇的。即使现在的网络,从计算系统角度来看它可能相当大的,但实际上它比相对原始的脊椎动物如青蛙的神经系统还要小。
由于更快的CPU、通用GPU的出现更快的网络连接和更好的分布式计算的软件基础设施,模型规模随着时间的推移不断增加是深度学习历史中最重要的趋势之一。人们普遍预计这种趋势将很好地持续到未来。
与日俱增的精度、复杂度和对现实世界的冲击
深度学习的另一个最大的成就是其在强化学习( reinforcement learning)领域的扩展。在强化学习中,一个自主的智能体必须在没有人类操作者指导的情况下,通过试错来学习执行任务。 DeepMind表明,基于深度学习的强化学习系统能够学会玩并在多种任务中可与人类匹敌Mnih et al.,2015)。深度学习也显著改善了机器人强化学习的性能。